Hi,
I am working on developing some advanced deck features that will allow users to upload their own third party materials to their Ankihub decks, essentially automating the image copy/paste process and solving the copyrighted 3rd party material dissemination issue.
Part of this includes dynamic loading of webpages stored in the collection.media folder that essentially replace traditional images.
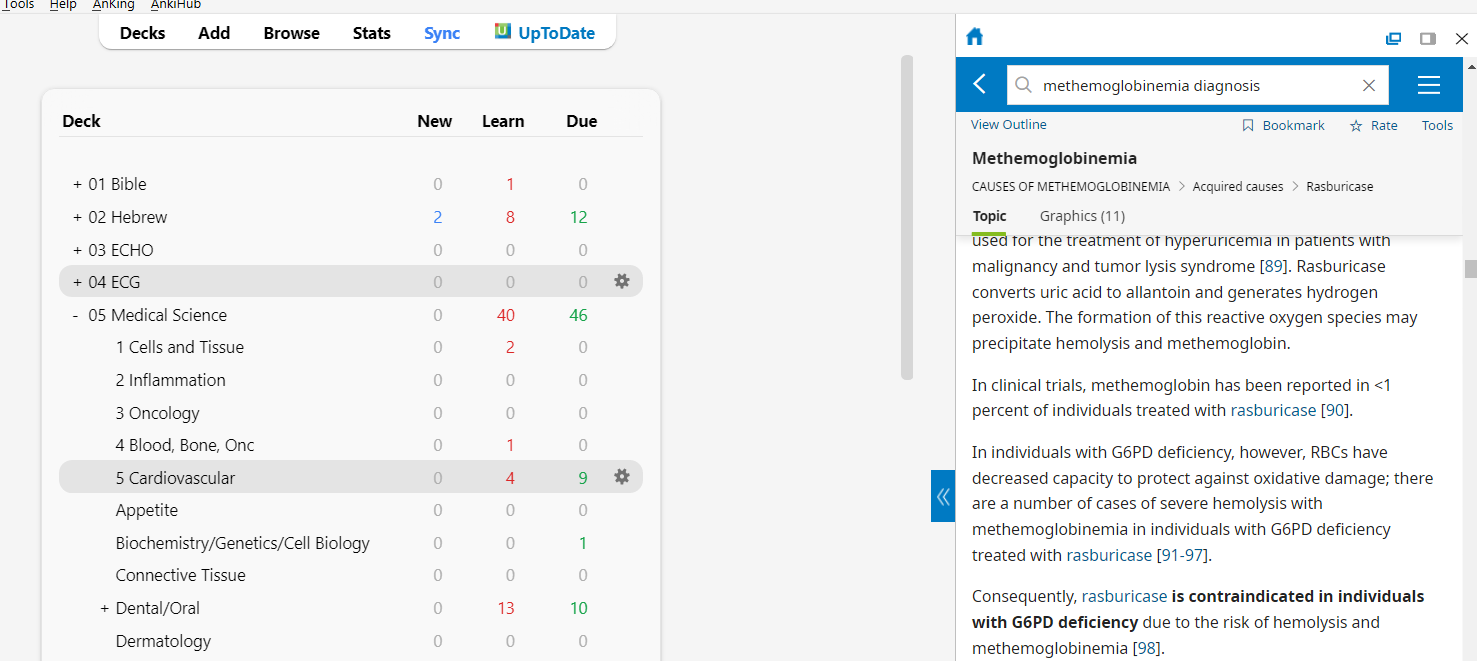
Here’s a practical example: If a user wants to use FirstAid in their AnKing deck, they download an addon that automatically takes their purchased FirstAid PDF, parses the PDF into a responsive webpage that “acts” like a pdf reader, and then generates tag-matching suggestions where the user can confirm that the tags match the bookmark in the PDF that they would want to navigate to given that tag. Once the user clicks on the “First Aid” button, their pdf will appear as an iframe and navigate to the exact position that the tags indicate, with an accompanying collapsible outline menu.
Because this is an html page, it works with addons such as the Amboss addon, with some minor tweaks.
This is already a reality. I’ve implemented the entire process, and now only need to create an addon that does it automatically for any PDF. See below:

The only issue I have now encountered is that when I try to upload non-copyrighted versions of media using this solution to AnkiHub, all of the media files get renamed, which of course breaks everything. I know that there is a good reason for this, but Is there any way that I can exempt files from being renamed, similarly to how adding “__” before the filename exempts it from being cleaned up by anki?
Edit: also, to head off any questions about this, I’ve worked out a way to make it so when users subscribe to a deck like this on AnkiHub, it automatically inserts into their actual AnkiHub deck. It’s simple to just reference all of the media as srcs in a dummy card so that AnkiHub uploads the images, then have some quick external javascript code insert the content into the actual AnkiHub field.
Thanks!
6 Likes
This is super cool, @conwork - thanks for sharing! I could see coming up with a really cool workflow that would work well with AnkiHub and provide a seamless integration with additional resources like First Aid.
It would might make sense to define a canonical location for users to store additional resources such as the First Aid PDF, etc. We could also automatically map the additional resources to the appropriate notes when users have the resource locally.
This way, users can just load up their local additional resources folder with PDFs, slides, etc, that can automatically be processed and linked to notes.
@jakub.f , can you comment on the issue about renaming images?
1 Like
This looks cool, but I don’t fully understand what this does / how it works. Why is there a need to upload media files if the media files are contained in the PDF? I also don’t understand the part about tags and tag suggestions. What kind of tags are these? Anki tags? Why are they needed for navigation in the PDF?
2 Likes
Hi,
This is a great question. Essentially, this was meant to solve for these problems:
1.) Copyright laws for 3rd party resources continue to be a source of tension for Anki users. First Aid images are essential to the AnKing deck, but are not distributed legally. The FA team refuses to provide a legal pathway for distribution.
2.) Many third party resources distribute material in PDF form, but Anki does not support PDFs.
3.) Even if Anki were to support PDFs, preserving current functionality of screenshots (having the image you need when you need it) is not currently possible with PDFs.
The following process is what I developed as a solution to this problem:
1.) Start with a pdf document supplied legally by a third party company.
2.) Automatically parse and create Bookmarks within the PDF, or verify that current bookmarks have the level of detail desired. I have had success automatically parsing based on font size and color for resources like First Aid. [These will later be mapped to Anki tags]
3.) Optimize PDF with Ghostscript. [Helps reduce space, remove duplicate fonts, etc]
4.) Parse through the PDF with a modified version of pdf2htmlEX that I optimized for Anki use. [This converts the PDF to html code so that it can be inserted into anki as an iframe with cross-platform support and lazy loading optimizations while retaining real text]
5.) Assign Anki tags to the appropriate bookmarks from the PDF document. [This will allow the code to dynamically build a list outline based on tags on the card, and automatically navigate to the correct section.]
6.) Drag and drop all resources into the collection.media folder, and amend the back note template to execute the startup script.
There are variations to all of these steps that can be discussed. This is just the process I found the most helpful. It allows for fast loading of multi-thousand page PDF documents across Anki platforms. Ideally, in the future, it would even be possible to adjust the zoom level for each bookmark so that it functions almost identically to today, but totally legal and dynamically updated based on Anki tags. Want to add a FA image to another card? Literally just tag it and it will show up.
Of course, if integrated with Ankihub, you could just map the tags to bookmarks once and take care of that problem on the backend. Essentially, a user would just process the pdf with an anki addon, choose the mappings for their version (FA 2020, FA 2021, etc), and have fully-functional 3rd party resources obtained legally and even more useful (indexable by Amboss addon, able to navigate through the whole resource, etc).
Honestly, this is just one application of local htmls inserted through iframes. Exploring others as well. All of this is kind of off topic though. The major issue is that AnkiHub cannot function without renaming all of my media.
4 Likes
You can currently upload media using the Upload media for deck action in the AnkiHub menu on the main Anki window and this won’t rename the media files. I think this can be used as a solution for this. However you can only use this if you are the owner of the deck. It just uploads all media files referenced on the decks notes which are in the local collection without renaming them.
Another solution could be to rename the media references in the html of the converted pdf using a script. The script could match up renamed images to the original image names by comparing images and then use the mapping between media names to replace the image references in the html.
I’m thinking about looking into the possibility of not renaming media files, as it also has some downsides in other situations. We could maybe make that change as part of the current project related to the media sync. (The hash could be stored in the table entry for the media file instead of in the filename.)
I wonder if we can just automatically map PDF pages to notes based on a similarity search that compares the the PDF page (image and text) with the note contents. This would make the tagging system unnecessary. Notes could automatically get the correct PDF page references based just on the note’s text.
2 Likes
Can you make this work with the UpToDate Anki Addon? I assume it would be pretty compatible?
1 Like
Would that mean that a person could pause their review and go to the page in the book to read it, more easily? Or am I misunderstanding what you’re saying?
Yes. We can make this work for any web site or PDF document.
Yes, theoretically. Although, I think this kind of thing would be better implemented by Amboss. I’ve already reached out to them in the past about adding UpToDate integration into the Amboss addon.
You could easily just insert uptodate as an iframe into cards. you may even be able to integrate in the card text as a table of contents to overlay on top of the iframe and add in a link system to search those topics.
You know, maybe this is better implemented as an iframe. I think it could be cool.
1 Like
Yeah, this a future step. I think that it would take a little more work to get this done though. It can be difficult, because sometimes the full context of a card isn’t stated in the card, or you get false positives from a word that is matching another concept (one example is something like “temporal heterogeneity” in cancer/biochem stuff matching “temporal” in “temporal bone”).
I was planning to add this in a different drop-down under the “tag-based outline” dropdown as a “keyword outline” dropdown or something like that.
Isn’t the context readily available by reading the tags and analyzing the copyright free images for most cards?
AMBOSS isn’t going to want to do that - they’re trying to compete with UpToDate from the looks of it.
Can you iframe it if it requires a login?